Loss Landscape Poster - 17"x22"








Loss Landscape Poster - 17"x22"
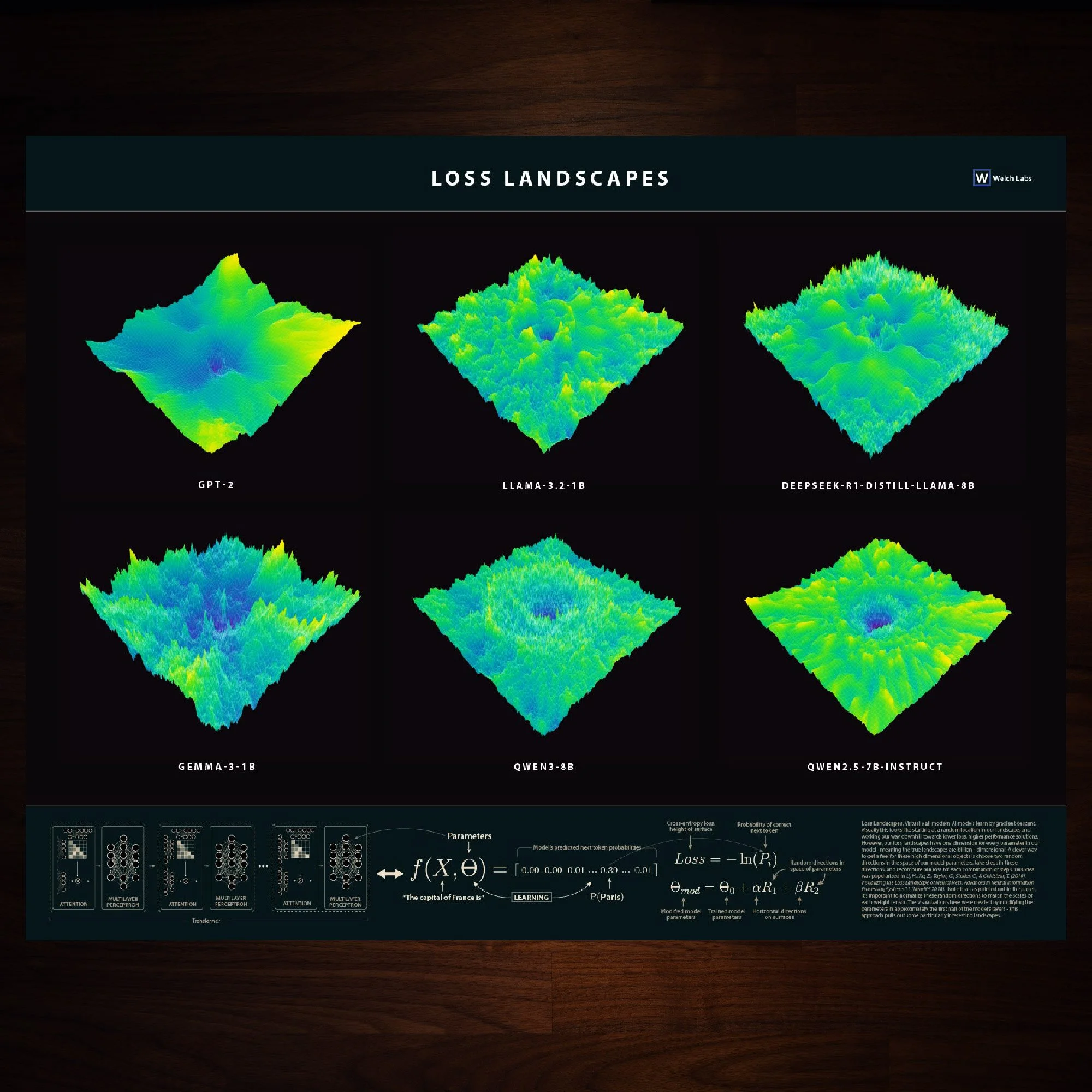
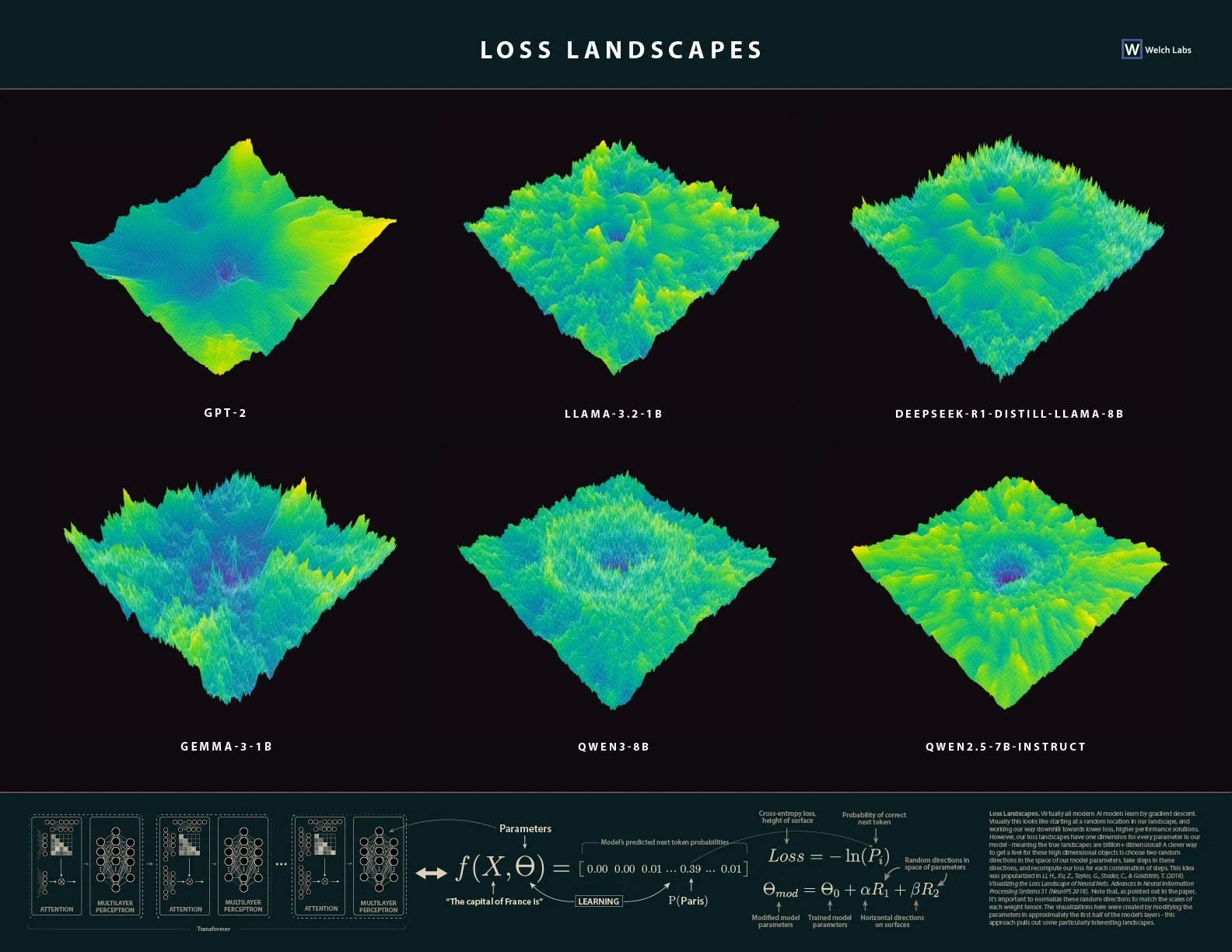
This poster includes six beautifully illustrated large language model loss landscapes. Top and center you’ll find the Llama 1 billion parameter landscape covered in the corresponding Welch Labs video - to the left we have a simpler model, GPT-2, which results in a smoother simpler landscapes. In the upper right you’ll find a distilled version of DeepSeek-R1, which interestingly has larger smooth areas than Llama, this may be because DeepSeek has been instruction tuned. On the bottom row you’ll find Gemma 1B, this is the smaller open source version of Google’s Gemini model, and on the bottom right we’ve included a couple variants of the popular Qwen models - it’s again interesting here to compare instruction tuning to just pretraining. The bottom of the poster includes some of the key figures from the video that explain how we’re computing loss landscapes.
Beautifully printed high resolution poster
Printed using imagePROGRAF PRO-1100 on high quality Canon Pro Luster paper using Canon LUCIA PRO II Ink for outstanding color and fine detail reproduction
Fits well in most standard 17×22” frames, the poster is pictured in this frame.
Frame not included
Shipped rolled in 3” tube
Only shipping to US addresses currently, please allow 3-8 business days for shipping & handling
More About This Poster
Virtually all modern AI models learn by gradient descent. Visually this looks like starting at a random location in our landscape, and working our way downhill towards lower loss, higher performance solutions. However, our loss landscapes have one dimension for every parameter in our model - meaning the true landscapes are billion+ dimensional! A clever way to get a feel for these high dimensional objects is to choose two random directions in the space of our model parameters, take steps in these directions, and recompute our loss for each combination of steps. This idea was popularized in Li, H., Xu, Z., Taylor, G., Studer, C., & Goldstein, T. (2018). Visualizing the Loss Landscape of Neural Nets. Advances in Neural Information Processing Systems 31 (NeurIPS 2018). Note that, as pointed out in the paper, it’s important to normalize these random directions to match the scales of each weight tensor. The visualizations here were created by modifying the parameters in approximately the first half of the model’s layers - this approach pulls out some particularly interesting landscapes.